
Szabó András
Mesterséges intelligencia a KRÉTA rendszerben
Köszönöm szépen. Ilyen felvezető után tényleg azt mondom: komoly kihívások elé állítanak, hogy tényleg valami újat tudjak mondani.

Élvezettel hallgattam az előző előadást, főleg azok a képek ragadtak meg, amelyek azt mutatták be hogyan képzelik el a következő évszázadban az oktatást.
Előjöttek viszont azok a képek bennem, amelyek a múlt évszázad '20-as, '30-as éveiben készültek, hogy akkor hogyan képzelték el a jövőt az emberek repülő autókkal, robotokkal, meg egyebekkel.

Azért nem minden jött be. Végiggondoltam közben, hogy minden évtizednek volt egy ilyen nagy hype-ja, ami vagy bejött, vagy nem.
A '80-as években a személyi számítógépek jöttek be, a '90-es évek az internetről szóltak, ezek bejöttek. 2010-ben a mobilok, a mobileszközök jelentek meg, ezek is megmaradtak. A 2010-es években a VR világ lépett be. Na, az nem sikerült, ott azért nem sikerült olyan áttörést elérni.
Azt gondolom, hogy 2020-as évek a mesterséges intelligenciáról fognak szólni. Ami érdekes benne, hogy gyakorlatilag azok az alapalgoritmusok, amik a mesterséges intelligencia alapjait képezik, azért azok elég régóta velünk vannak, hiszen már a '90-es években megvoltak ezeknek az alapjai.
Mi az, ami változott? Egy hatalmas változás az, hogy most már iszonyatosan nagy mennyiségű adatot vagyunk képesek feldolgozni. Oda fejlődött a számítástudomány, a számítástechnika, hogy ezeket az adatokat már lehet különböző AI algoritmusokkal feldolgozni. Illetve, hogy a ChatGPT sikerére mindenki azt mondja, hogy végre egy olyan nyelvi előtétet tudtak elővenni – szintén a kapacitások miatt –, ami már teljesen emberközeli élményt ad.
Én bevallom őszintén, szubjektíven állok a kérdéshez, mert én támogatom ezt a technológiát. Saját munkámban is nagyon sokat szoktam használni, és azok a félelmek, amiket ezzel kapcsolatban mondanak – nagyon jó volt a vonatos példa az előző előadáson –, hát minden új technológiával vannak problémák.
Amikor a KRÉTA-ról beszélünk, mindenki azt gondolja, hogy ez egy elektronikus napló, vagy iskolaadminisztrációs rendszer.
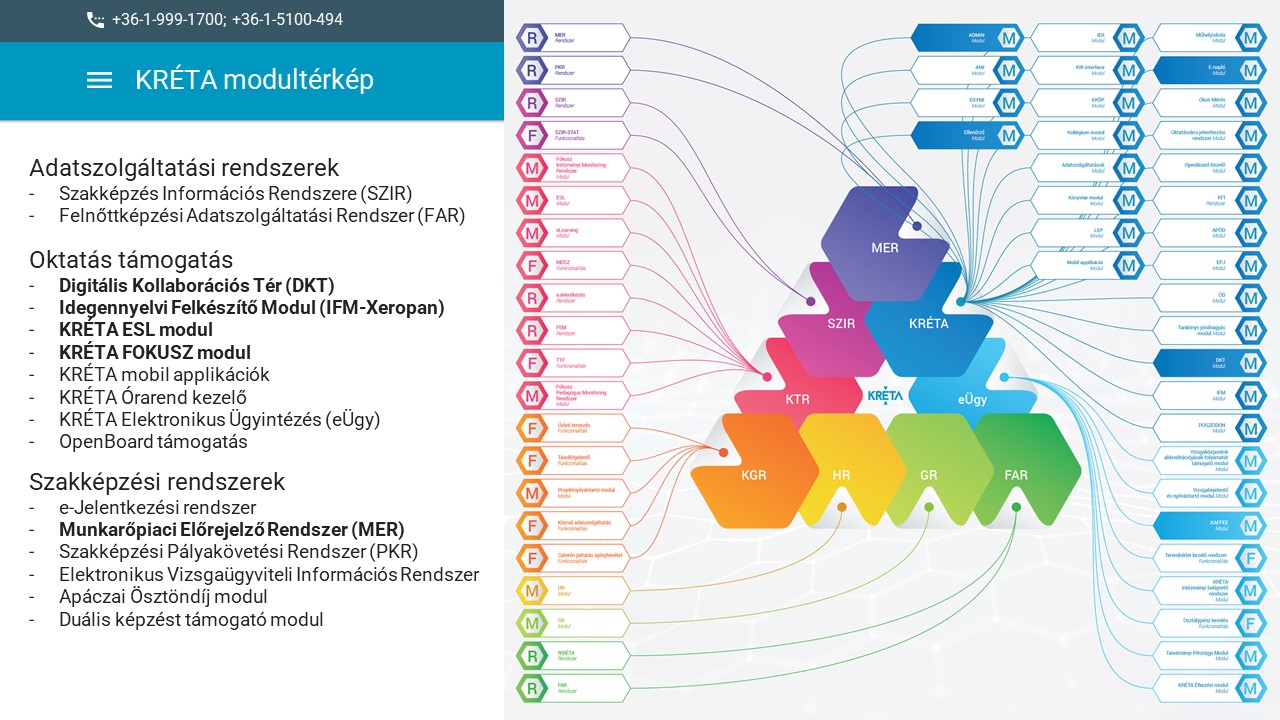
Itt ezen az ábrán azt szerettem volna feltüntetni, hogy rengeteg minden mással is foglalkozunk. Sok olyan modulja van a KRÉTA-nak, amelyek talán még az oktatásban nem annyira ismertek. Való igaz, hogy elsősorban oktatási szoftvereket fejlesztünk, de ezek a szoftverek között van olyan, ami nem annyira szorosan kapcsolódik az oktatáshoz, de használunk benne mesterséges intelligencia elemeket.
Azt is megjegyezném, hogy ezek fejlesztésének a többsége azért a „AI hype” kirobbanása előtt kezdődött, tehát mi már akkor elkezdtünk ilyenekkel foglalkozni. Néhány olyan modult szeretnék bemutatni majd, aminél már használunk ilyen eszközöket.
Az első az úgynevezett IFM modul, ez egy idegennyelv-oktató modul. Ez tulajdonképpen a Xeropan nevezetű szoftver. Ez egy klasszikus felhasználási területe az AI-nek. A nyelvoktató szoftver abban használ MI-t, hogy olyan környezetet, olyan párbeszédeket generál a mesterséges intelligencia segítségével, amivel tényleg olyan érzése van az embernek, hogy egy szállodai recepción beszélget, vagy elmegy egy étterembe. Vagy éppenséggel egy üzletbe, és akkor olyan feladatokat, olyan szituációkat talál ki, amelyek ténylegesen élvezetessé teszik ezt feladatot.

Próbálja azt a környezetet megvalósítani, azt a környezetet előállítani, ami valóságban előfordulhat. Ne nagyon legyen ilyen repetitív, azaz ne nagyon ismétlődjön ugyanaz. Az AI-t teljesen jól fel lehet erre használni, hogy ugyanazon feladat ismétlésekor lehet, hogy egy teljesen más attitűddel rendelkező eladóval vagy recepcióssal kell beszélgetni.
Tananyagfejlesztéshez is használunk ilyen megoldásokat. Gyakorlatilag ez megint azt jelenti, hogy a rendelkezésünkre álló tananyagokat felcímkézzük, és ezekből a címkézésekből próbáljuk kitalálni – próbálja a rendszer kitalálni – azt, hogy a felhasználó éppen milyen tanulási útvonalat követ, mi az ő nyelvi készségeinek a szintje, és ez alapján ajánl különböző eszközöket.
A hanggenerálás, ez is egy nagyon fontos része. A mesterséges intelligencia mindig arról szól, hogy próbáljuk meg az embert leutánozni.
[1]Aki ezen a területen van, az ismeri a Turing tesztet. A '40-es években az Alan Turing nevezetű kódfejtő találta ezt ki. Ez arról szól, hogy van két szoba. Az egyik szobában egy ember van, a másik szobában egy gép van. Mindkét szobának feltehetünk kérdéseket, kommunikálhatunk velük, és az a feladatunk, hogy eldöntsük, hogy melyik szobában van az ember, és melyik szobában van a gép. Hogyha ez nem sikerült, akkor megszületett a mesterséges intelligencia.
Tehát amikor definiálni kell az AI-t, sok ember nyakatekert definiálásokat hoz, hogy mi is az AI, hogy lehet ezt definiálni. Alan Turing a 40-es években ezt viszonylag egyszerűen megoldotta hétköznapi eszközökkel. Turing kb. öt percet mondott, azaz hogyha öt perc után nem tudja eldönteni, akkor az már AI-nek tekinthető. Most már ezt az öt percet szerintem azért jóval meghaladtuk.
[1] A képek mesterséges intelligenciával generálva készültek.

A következő, ahol a mesterséges intelligenciát alkalmazni lehet a digitális kollaborációs tér, a KRÉTA DKT. Ez egy tanulási tér, ahol a diákok a klasszikus módon hozzájuthatnak különféle tananyagokhoz. Mindenféle olyan interaktív tevékenységet el lehet végezni, amit mondjuk a Google Workspace vagy a Classroom nagyjából tudott. Az ebben lévő MI fejlesztésünk még nincs kész, tehát ezt most még ne keressék benne, de itt a következőket tervezzük a jövőre vonatkozóan.
Viszonylag rövid számítással ki lehet mutatni, hogyha van egy történelemtanár és – például az esszékről volt itt szó az elmúlt előadásban – mondjuk írat egy 40 fős osztályban egy esszét. Ha minden beadott esszével csak öt percet foglalkozik a javításnál, akkor körülbelül hány órát fog neki igénybe venni a javítás. Nem lehetne azt csinálni, hogy ezeket az esszéket beadjuk az AI rendszereknek, és mondjon róla véleményt? Nem azt mondom, hogy rögtön osztályozza is le, valójában azt mondom, hogy ki tudja javítani. Vagy legalábbis valami összefoglalást tud erről adni. Hozzáteszem, ilyen rendszerek vannak. Például a Microsoft Teams-be is be van építve már egy olyan funkció, hogy egy értekezletet fel tud venni, és a végén arról egy írásbeli összefoglalót a készíteni. Nem kell jegyzetelni menet közben valamelyik résztvevőnek.
Joggal merülhet fel a kérdés, amikor egyszer így beszélgettünk erről, hogy „Hú, hát itt megint a tanároknak elvesszük a munkáját”, hogy már javítani se kell, mert helyettünk megcsinálja.
Visszalőnék ezzel egy picit: gondolom, a tanári pályafutása során mindenki találkozott olyannal, amikor pedagógus szülő – például történelem tanár szülő – jön be lobogtatva a gyerek dolgozatát, hogy ez nem hármas, ez biztos, hogy nem hármas, hogy ő olyan szakmai hírnevét teszi erre föl. Tehát már most is van ilyen. A gyerekek is ezt fogják csinálni – csinálják is már egyébként –, hogy például megkapja a dolgozatát, meg kap rá egy érdemjegyet, majd elmegy ehhez a ChatGPT-hez, vagy valami más rendszerhez, beírja, majd odamegy a tanárhoz, lobogtatva az eredményt, hogy nekem a ChatGPT azt mondta, hogy ez 95%. Ugye?
Tehát attól, hogy mi elmenekülünk egy eszköztől, vagy nem használjuk, az még nem azt jelenti, hogy a másik oldal nem fogja használni. Ilyesmit szeretnénk a DKT-ban megvalósítani. Vannak már erre vonatkozóan kísérletek. Vannak már működő rendszerek, amik képesek ezt megcsinálni. Azt nézzük meg, hogy ezt mennyire lehet a különböző területeken alkalmazni.

A harmadik rendszerünk, ami ilyesmit használ, ez egy picit távolabb áll az oktatástól, de azért idehoztam, hiszen itt is egy AI-ről van szó. Van egy munkaerőpiaci előrejelző rendszere a KRÉTA univerzumnak, ez a MER.
Minden állásközvetítő cégeknek negyedévente fel kell vinnie az álláshirdetések adatait egy központi adatbázisba, hogy épp a magyar munkaerőpiacon milyen munkaerőt keresnek. Nagyon sok esetben persze lehet egy-egyes megfeleltetést csinálni, hogy igen, kőművest keresünk, vagy igen darukezelőt keresünk, aminek lehet egy megfelelő szakmát vagy megfelelő szakképesítést találni a magyar oktatási rendszerben. Viszont nagyon sok esetben ez nem így van. Például azt mondja valaki, hogy társasházkezelőt keresnek. Ebben az esetben ezt nem lehet eldönteni, hogy ők tulajdonképpen mit keresnek? Miből lehet dönteni? Az álláshirdetéseknél van egy szöveges leírás, ahol leírják, hogy milyen kompetenciákat várnak el, és ez alapján a rendszer meg tudja állapítani, hogy tulajdonképpen egy olyan embert keresnek, aki képes annál a társasháznál a villany, a gáz és egyéb dolgokat rendben tartani. Tehát valószínűleg egy ilyen végzettségű szakemberre van szükségük.
Most az ún. mélytanulást, a Deep Learning-et használjuk, hogy ezeknél az álláshirdetéseknél megpróbáljuk megállapítani a leírt szöveg segítségével azt, hogy ők valójában milyen szakképesítésű, vagy milyen szaktudású embereket keresnek. Ebből iteráljuk, hogy akkor az oktatásban most éppenséggel mondjuk milyen végzettségű embereket kellene képezni. Ez a rendszer a szakképzésre készült, tehát itt kifejezetten a középfokú szakképesítésekre és az ahhoz kapcsolódó felnőttképzésekre lövünk vele. Ez egy öntanuló rendszer. Itt – mivel ennek a fejlesztését 2019 környékén kezdtük – még nem ChatGPT-t vagy hasonló rendszert használtunk, hanem ténylegesen vettünk egy mélytanuló algoritmust, és azokat fejlesztgették a kollégáim.
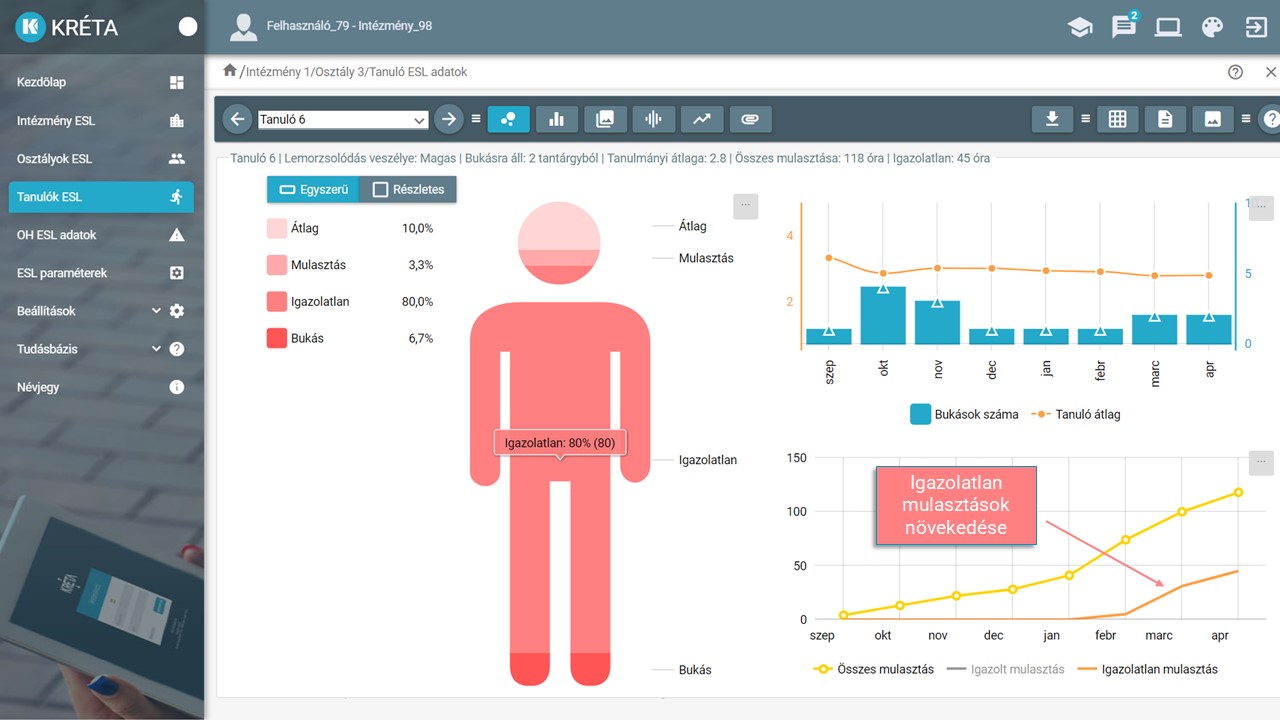
A következő ilyen MI alapú rendszer valószínűleg találkozhattak már. Ez a korai iskolaelhagyás, a korai lemorzsolódásnak a megelőzésére szolgáló rendszer, a KRÉTA ESL.
Sajnos jelentős probléma a magyar oktatásban, hogy a diákok végzettség nélkül hagyják el az iskolát, menet közben befejezik, és ez semmiképpen sem egy hasznos dolog, sem az ő életére vonatkoztatva, sem pedig nemzetgazdasági szempontból. Hiszen pénzt, paripát, fegyvert adtunk arra, hogy ezt a gyereket képezzük, de ez nem hasznosult. Ennek a rendszernek az a lényege, hogy a lemorzsolódás az nem úgy jön létre, hogy a tanuló egy szép márciusi napon felkel, és azt mondja: Na, én ma lemorzsolódok.
Ez nem így működik, hanem vannak előzményei. Azt figyeltük meg a rengeteg adatból, ami rendelkezésre állt – volt ilyen prekoncepció és ezt megerősítette –, hogy a lemorzsolódásnak mindig vannak előzményei. Nagyon sok esetben általában valamilyen esemény hatására történik ez az egész. Tehát nagyon sokféle lehet. Családi okok miatt elveszíti a családfő a munkáját, el kell menni a tanulónak dolgozni stb.
Most nem is az okokat kutatjuk, hanem azt látjuk, hogy a lemorzsolódás elkezdődik azzal, hogy a gyerek egyre többet kezd hiányozni, elkezd romlani az átlaga és így tovább. Van egy pont, amikor már nem nagyon lehet mit csinálni, tehát hogyha valaki elért mondjuk 70–80 igazolatlan órát, akkor a szabályozás szerint ez alapján már kevésbé lehet vele mit kezdeni.
Viszont pontosan az a lényege, hogyha ezt a folyamatot időben észreveszi az osztályfőnök vagy az adott tanár, akkor ez megállítható. Tehát a rendszerünk az arról szól, hogy a diákoknak minden egyes időpillanatban csinál egy profilt különböző súlyszámok alapján. Jelen pillanatban 12 olyan értéket határoztunk meg, ami alapján felcímkézi vagy meghatározza a gyereknek az indikátorrendszerét, és ez alapján próbálja egy picit prediktív módon megjósolni, hogy ha ez a tendencia folytatódik, vagy ha ezek az attitűdök maradnak, akkor ő veszélyeztetett-e vagy sem a lemorzsolódás szempontjából. Ezt különböző grafikonokon és diagramokon próbálja ábrázolni a tanárok, illetve az osztályfőnökök részére.
Úgy látjuk, hogy a rendszert – főleg a szakképzésben – nagyon sokan használják és nézegetik. Tehát minden egyes esetben az osztályfőnök vagy az adott szaktanár végigpörgeti az osztály tanulóiról szóló lapokat/oldalakat – hetente egyszer vagy havonta egyszer –, akkor azért rögtön kiugrik neki, hogy ha valakivel gond van.
Nyilvánvaló dolog, hogyha ezt meg lehet a diákokra csinálni, akkor lehet ilyesmit a tanárokra is csinálni. Ez most szintén aktuális téma, a pedagógus-értékelési rendszer, amit szeretne bevezetni az oktatási kormányzat. Nagyon sok vita van róla, ma reggel is olvastam ezzel kapcsolatban levelezést. Ez is már régóta benne van a KRÉTA-ban, bár egy picit félreértelmezik, mert azt gondolják sokan, hogy ez értékeli a tanárokat ilyen módon.
Valójában nem azt csinálja, hanem egyfajta monitoringot, olyan komplex indikátorrendszer alapján kidolgozott mutatókat állapít meg, ami alapján a munkáltató azt tudja eldönteni, hogy az adott tanár az adott területen mennyire jól dolgozik. Ez a „jól dolgozik” mindig egy nehéz dolog, mert mihez viszonyítunk. Egy budai elitiskolában sokkal könnyebb dolgozni, mint egy borsodi kisiskolában. Ez igaz. Ezt senki nem vitatja. Ezért a KRÉTA FOKUSZ mindig az intézményi átlaghoz viszonyít. Tehát ő nem azt mondja, hogy abszolút értékben valaki fölfele vagy lefele eltér, hanem megnézi, hogy az intézményi átlaghoz képest ő most éppen hol helyezkedik el. Ezért nincs benne olyan, hogy én mindenben nagyon jó vagyok, másrészt pedig olyan mutatókat is tud mérni, illetve előállítani, amire talán nem is gondolunk.
Egy példát engedjenek meg ezzel kapcsolatban. Egy vegyipari iskolában van egy labortanár, aki gyakorlatot tart, ezek 8 órás gyakorlatok, de ott viszonylag kevés gyerekkel, 8–10 fős csoportokkal lehet dolgozni. Ő a 24 óráját három nap alatt letudja, mert a háromszor nyolcórás gyakorlattal, háromszor nyolc vagy háromszor tíz gyerekkel, harminc gyerekkel dolgozik összesen. Tehát ha ő írat egy dolgozatot, akkor neki 30 dolgozatot kell kijavítania.
És vegyünk egy fizikatanárt, vagy egy történelemtanárt, aki tanít vagy nyolcféle osztályban, körülbelül 300 gyereket.
Ha ő irat dolgozatot, az 300 gyereknek a dolgozatjavítását jelenti. Érezzük, hogy mind a kettő ugyanúgy a 24 óráját megcsinálja, meg elvégzi rendesen a munkáját, de azért van különbség a két tanári terhelés között.

Tehát ezeknek az indikátoroknak a beépítése és a mérése – amelyek fontosak a pedagógiai munkában –, illetve ezeknek inkább a kiértékelése, amire az AI-t használjuk. Továbbá fontos az egyes trendeknek a megjelenítése.
Ez már inkább intézményekre vonatkozik, hogy az intézménynek a különböző indikátorok szerinti fejlődése, és ezeknek a korrelációja mennyire hat együtt. Nyilvánvalóan evidens dolgokat ki tudunk mondani, hogy mondjuk a mulasztások száma és a tanulmányi eredmények között abszolút összefüggést lehet látni. Valaki minél többet mulaszt, annál rosszabb a tanulmányi eredménye. De itt is rengeteg olyan rejtett összefüggés van, amit ki lehet mutatni. Ezt régebben adatbányászatnak hívtuk. Most már divatosabb az AI kifejezést használni. De valójában továbbra is arról van szó, hogy azt a hatalmas mennyiségű adatot, ami a KRÉTA-ban benne van, hogy lehet megfelelően feldolgozni.
Mondjuk ki tud rajzolni a pedagógusértékelésnél a következő ábrán láthatóhoz hasonló heat-mappet. Ez egyszerűen arról szól, hogy a különböző indikátorok alapján jeleníti meg az indikátorokat: ami zöld, abban a tanár jobb az átlagnál – például az ő órájáról kevesebbet hiányoznak a gyerekek. Az ő osztályzatai általában jobbak, mint az intézményi átlag stb.
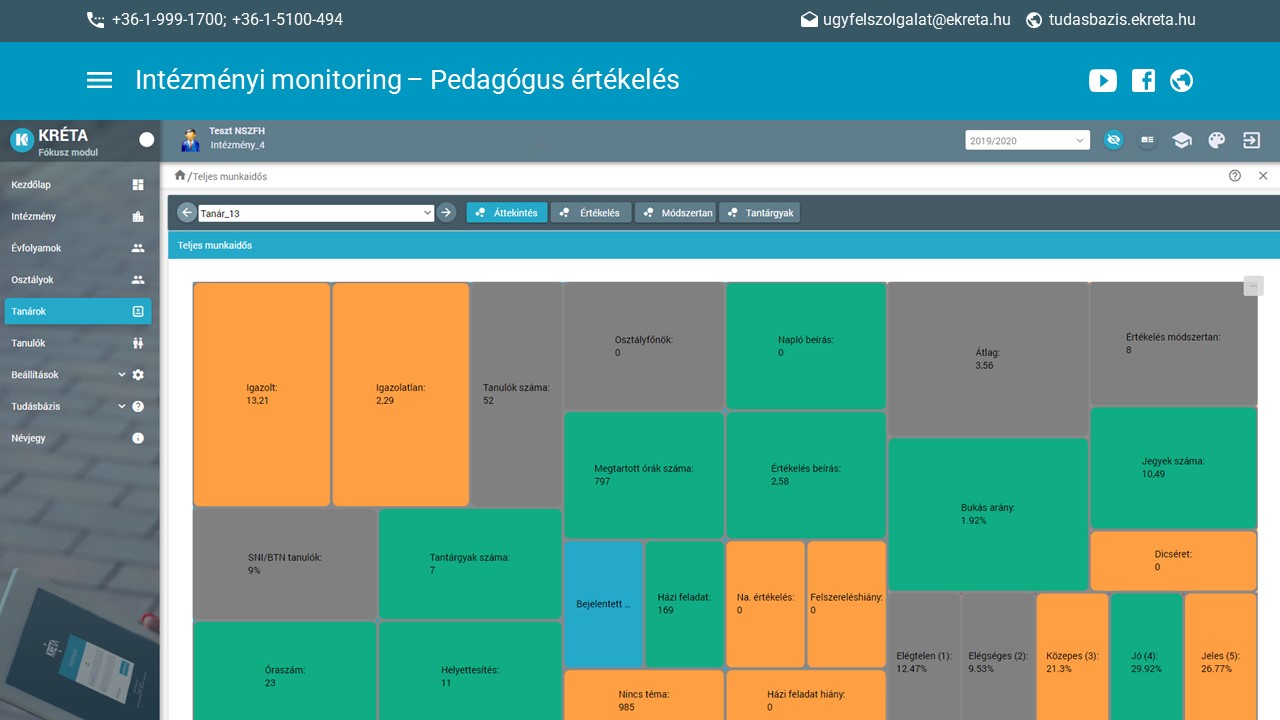
És vannak a sárgával jelzettek, ahol az intézményi átlagtól negatív irányba tér el.
Köszönöm szépen, ahogy meghallgattak.